Robots.txt : quels sont les principes et bonnes pratiques à respecter ?

Qu’est-ce qu’un fichier robots.txt ?
Le robots.txt est un fichier texte placé à la racine d’un site internet. Sa fonction est d’indiquer aux moteurs de recherches et autres robots (appelés également spider) le comportement qu’ils doivent adopter quand ils cherchent à indexer un site web. Ainsi, il permet de préciser les contenus qui doivent être explorés et ceux qui doivent être ignorés par les moteurs de recherche. A noter que ce fichier est le premier qui sera analysé par les bots.
Pourquoi est-il utile ?
Comme évoqué, le fichier robots.txt donne des instructions aux robots des moteurs de recherche qui analysent le site web. Par défaut, Google (et les autres robots) s’autorise à crawler toutes les URLs d’un site internet. Une configuration adaptée du robots.txt permet ainsi :
- De donner des directives claires pour ne pas indexer certaines pages,
- De bloquer le site pour certains robots indésirables ou non souhaités,
- D’économiser du budget de crawl (ou « crawl budget » en anglais). Concrètement, cela correspond au nombre de pages que Googlebot va crawler lors de son passage sur un site. Cette limite est fixée en fonction de plusieurs critères : taille du site, vitesse d’exploration, fréquence de mise à jour du site, qualité des contenus, etc.
- D’éviter que certaines pages soient indexées si le blocage est prévu dès la mise en ligne d’un site web.
- D’indiquer l’URL du fichier sitemap.xml. Ce n’est pas une obligation car ce fichier peut très bien être uniquement déclaré directement dans la Search Console Google et dans Bing Webmaster Tools. A noter que l’accès à ce fichier étant public, n’importe qui aura connaissance de l’URL du sitemap et de son contenu.
Quelle est la différence entre le fichier robots.txt et la balise Meta Robots ?
Le robots.txt sert à gérer le crawl avant que le crawler vienne consulter les pages d’un site internet. La balise meta robots, quant à elle, sert à gérer l’indexation une fois que le spider est venu consulter la page. Cette balise meta robots est placée dans le code html d’une page web pour interdire son indexation en utilisant la syntaxe suivante :<meta name = « robots » content = « noindex » />.
Par exemple, si une URL a déjà été indexée par Google, alors la bloquer dans le robots.txt ne changera rien (l’URL restera indexée). En effet, Google n’ayant plus l’autorisation de crawler la page, celle-ci ne sera plus crawlée et restera donc dans l’index telle quelle. Pour la désindexer, il faut autoriser son crawl, utiliser une balise meta robots noindex ou un entête HTTP X-Robots-Tag et ensuite faire une demande de suppression d’URL dans la Search Console.
Comment créer un fichier robots txt ?
Le fichier robots.txt peut être :
- Créé manuellement,
- Généré par défaut par le CMS au moment de l’installation (exemple : WordPress). Dans le cas de WordPress, la configuration du fichier par défaut n’est pas optimale. Il est recommandé de la modifier.
- Créé à l’aide d’outils en ligne (des générateurs de fichier robots.txt) qui sont cependant à utiliser avec prudence.
Lors d’une création manuelle, ce fichier doit être écrit en utilisant un simple éditeur de texte (tel que bloc note, ne surtout pas utiliser Word). Une fois rédigé, le fichier doit être déposé sur le FTP du site internet, à la racine du domaine.
Pour le modifier, il faut récupérer la dernière version en ligne pour le site, ouvrir le fichier, le modifier puis le déposer à nouveau sur le FTP à la racine du site web pour écraser la version déjà présente en production.
Comment le configurer ?
Pour le configurer correctement, il faut le rédiger avec pour objectif d’exclure le contenu qui ne doit pas être indexé dans les moteurs de recherche. Par exemple :
- Des types d’URL qui n’ont aucun intérêt pour le référencement (tri, modes d’affichage, etc.) et pouvant être du contenu dupliqué.
- Des rubriques du site (répertoires) qui ne doivent jamais être indexées.
- Des types de fichiers qui ne doivent pas être indexés (par exemple les PDF).
NB : Ce fichier étant accessible à tous, attention de ne pas y indiquer des URLs « sensibles ». Une solution dans certains cas peut être de protéger l’accès à la page par un mot de passe.
NB2 : Les URLs qui se font rediriger ne doivent pas être bloquées car les moteurs ne pourront pas se rendre compte de cette redirection.
NB3 : Un expert SEO peut vous aider à le configurer correctement en cas de besoin.
👉 Principes de base de la configuration du fichier robots.txt
- Un site internet contient un seul fichier robots.txt. Par contre, dans le cas d’un site avec des sous-domaine, chacun doit avoir son fichier robots.txt.
- Le fichier doit obligatoirement s’appeler robots.txt (avec un « s » à robots, en minuscules exclusivement) et non « robot txt ».
- Le fichier doit être accessible pour les robots à l’adresse « https://www.example.com/robots.txt » pour un site web ayant l’adresse suivante : https://www.example.com/
- Le fichier doit être encodé en UTF-8.
- Un fichier robots.txt est constitué d’un ou de plusieurs groupes.
- Chaque groupe se compose de diverses règles ou directives (instructions), avec une seule directive par ligne.
- 4 directives uniquement prises en compte par Google :
- User-agent : robot auquel le groupe s’applique. L’utilisation d’un astérisque (*) permet d’englober tous les robots d’exploration, à l’exception des différents robots d’exploration AdsBot, qui doivent être nommés explicitement.
- Disallow : répertoire ou page, relatifs au domaine racine, qui ne doivent pas être explorés par le user-agent.
- Allow : répertoire ou page, relatifs au domaine racine, qui doivent être explorés par le user-agent mentionné précédemment.
- Sitemap : emplacement d’un sitemap pour ce site Web. L’URL fournie doit être complète.
- Les caractères $ et * peuvent être utilisés pour préciser les directives : ce sont des wildcards.
- Les règles sont sensibles à la casse.
- L’URI doit commencer par un slash.
- Les espaces sont optionnels mais recommandés pour améliorer la lisibilité du fichier.
- La taille maximale d’un fichier robots.txt est de 500Kb, soit 62Ko (attention, ce qui dépasse sera ignoré par Google).
👉 Exemple de fichier robots txt
# robots.txt du site https://www. votresite.fr/ #
User-agent: * (Autorise l’accès à tous les robots)
Disallow: /wp-* (Pour bloquer l’accès à un répertoire commençant par /wp-)
Disallow: /login.php (Pour bloquer l’accès à la page https://www.votresite.fr/login.php)
Disallow: /checkout/ (Pour bloquer l’accès au répertoire checkout)
Disallow: /*.pdf$ (Pour bloquer toutes les URLs se terminant par .pdf)
Disallow: /*? (Pour bloquer l’accès aux URLs contenant un point d’interrogation comme https://www. www.votresite.fr/page.html?id=8)
Sitemap: https://www.votresite.fr/sitemap.xml (Lien vers le sitemap)
Vous trouverez sur le site https://robots-txt.com/ les ressources spécifiques à certains moteurs de recherche et certains CMS.
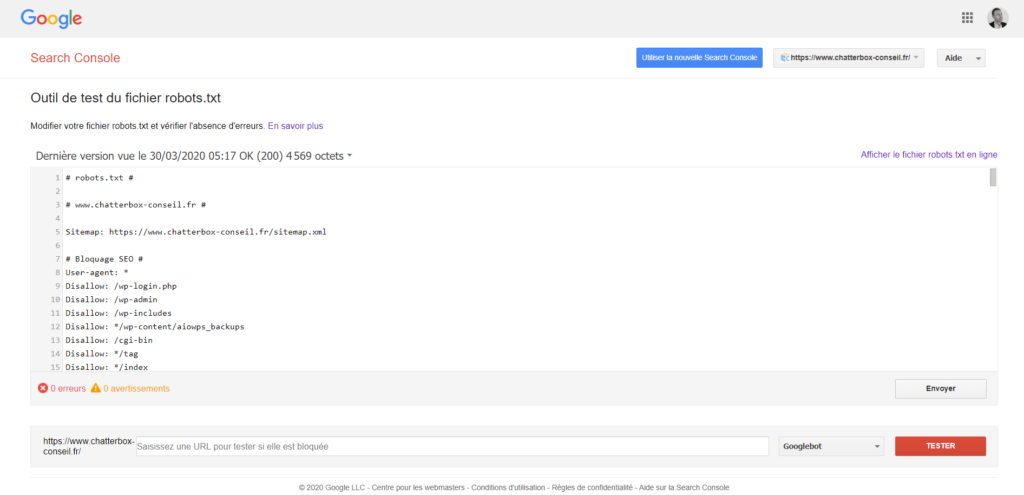
Comment tester un fichier robots.txt ?
Pour le tester un fichier robots.txt, il convient de pouvoir accéder au compte Google Search Console du site web en question. Ensuite, l’outil de test du fichier robots.txt mis à disposition par Google permet de vérifier, entre autres, que toutes les URLs importantes peuvent être indexées par Google. Vous pouvez également l’outil robots.txt validator.
Pour conclure, si vous souhaitez maîtriser un minimum l’indexation de votre site internet dans les SERPs, la création d’un fichier robots.txt est un prérequis indispensable. Si aucun fichier n’est présent, par défaut, les moteurs de recherche indexeront toutes les URLs qu’ils trouveront même celles que vous ne souhaitiez pas indexées.
> Pour aller plus loin :
Besoin d’aide pour configurer votre fichier robots.txt ?